こんばんは!
前回のブログでは、seleniumを使うための環境構築を行いました。
とりあえずChromeをseleniumで起動させることができるようになったので、今回は起動させたChromeを使って、Webサイトを触ってみよう、という回になります。
ChromeでWebサイトを開く
まず、
from selenium import webdriver
browser = webdriver.Chrome()
で、Chromeを起動する、というところは前回やりました。
そして、そのChromeで開くURLを指定してあげます。
シングルコーテーション(’)を使って、URLを囲ってあげます。
browser.get(‘https://yahoo.co.jp/’)
と入力すると、ヤフーのトップページが開きます。


↑
こんな感じです。
ちなみに、
browser.quit()
でブラウザを閉じることができます。
Yahooで検索してみる
次に、Yahooの検索窓へテキストを打ち込んで、検索をしてみます。
Chromeで開いたYahooの検索ボックスのところで右クリックを押して、開いたメニューから「検証」を選択します。

すると、Chromeの検証窓が開いて、HTMLの構造を確認することができます。

HTMLが普通に読める人はここから検索窓のタグを探してくれば良いのですが、HTMLソースを読み下すのはめんどくさいので、下記図の左上の赤丸の矢印マークをクリックします。

すると、マウスカーソルを動かして青くなったところをクリックすると、そのクリックしたHTMLのソースのところが青色でハイライトされるので、簡単に目的の箇所のHTMLが見つけることができます。

で、検索窓のHTMLは以下の青色の部分だねー、というのがわかりましたので、ここからプログラムで検索窓を指定してあげるための要素を取得します。
上の図の、検索窓をプログラムが探すための要素がゲットできれば良いのです、classとかnameとかいろいろと指定できる要素はあるのですが、今回はXPathを取得します。
上の図の青くなっている部分で右クリック→Copy→Copy XPath で取得します。

取得したXPathの値を使って、find_element_by_xpathを使い、
elem_kensaku = browser.find_element_by_xpath(‘//*[@id=”ContentWrapper”]/header/section[1]/div/form/fieldset/span/input’)
と打ってあげます。
上記で、検索窓の位置をプログラムが把握してくれるので、そこに検索するための文字を打ちます。
文字を打つには send_keys を使います。
「python入門」について検索する場合、
elem_kensaku.send_keys(‘python入門’)
という感じです。

検索窓に文字が入ったので、今度は検索ボタンをクリックするために、検索ボタンのXPathを取得して、
elem_kensaku_btn = browser.find_element_by_xpath(‘//*[@id=”ContentWrapper”]/header/section[1]/div/form/fieldset/span/button/span/span’)
というようにして、elem_kensaku_btnに検索ボタンのXPathを格納します。
そして、検索ボタンをクリックします。
elem_kensaku_btn.click()
↑
こんな感じで。
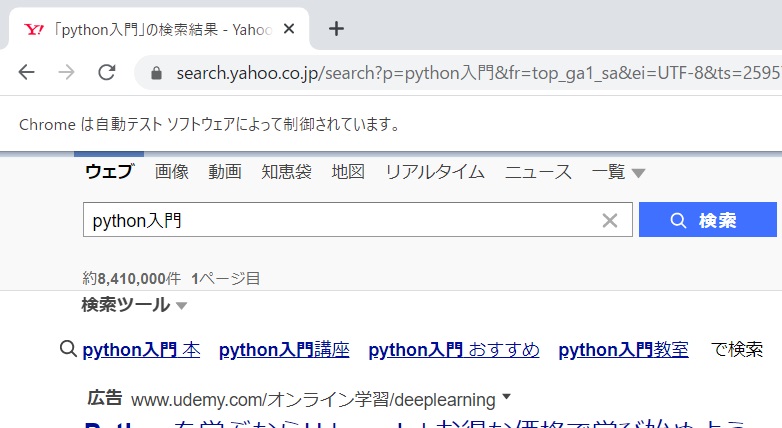
すると、以下のように検索結果が表示されます。
ここまでをまとめると、以下のようなプログラム文になります。

ブラウザ開いて→検索ページ開いて→文字を打ち込んで→検索ボタンを押す、
というところまで、自動でできるようになりました!