プログラムで指定したWebサイトにアクセスして、自動で必要なデータを収集してくることを
「Webスクレイピング」
と言います。
Pythonのいろいろな文法やらなにやらをパーツごとに勉強しても、
「で、具体的には何ができるのさ?!」
という気分になってきたので、ちょっと実用的なことをPythonを使ってやってみたいなぁ、と思い、Webスクレイピングをかじってみました。
Python Webスクレイピングの準備
PythonでWebスクレイピングをするときには、以下の2つのモジュールを使うことが多いです。
Requests(リクエスツ)
→WebページからHTMLを取得するモジュール
BeautifulSoup(ビューティフルスープ)
→HTMLを解析して必要なデータを取り出すモジュール
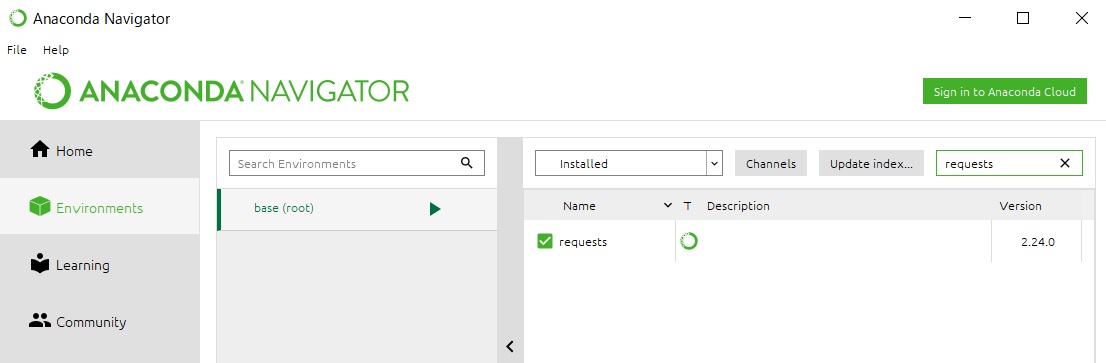
私の環境の場合、Anacondaをインストールした際に、すでにRequestsとBeautifulSoupの両方ともインストールされていました。
それぞれ、インストールされているかどうかはAnacondaの「Environments」から検索できます。
Requests↓
BeautifulSoup↓

HTMLの取得
Webスクレイピングの準備ができたら、さっそくやってみます。
ここで注意ですが、アクセス先のWebサーバに迷惑をかけないように、短期間に大量のリクエストをWebサーバに投げないように気を付けましょう。
(サイバー攻撃だと思われちゃうのでw)
インストールしておいた、requestsモジュールを使って、HTMLを取得します。
まず、requestsモジュールをimportでインポートします。
そして、requestsモジュールのget関数を使って、指定したURLのHTMLを取得します。
で、取得したHTMLをprintでテキスト表示すると、以下のようになります。
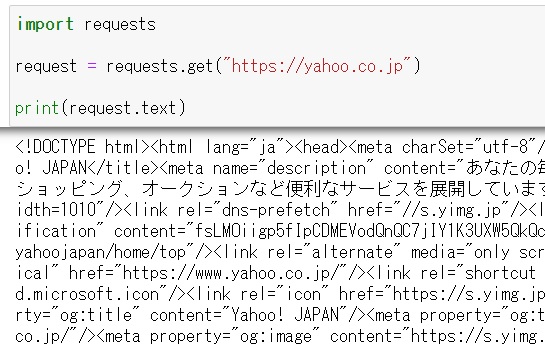
実際にWebスクレイピングする際は、取得したHTMLソースを見て、どこのタグからデータを取得してくればよいか?というのを探す必要があるので、HTMLのソースは読めるようになっておく必要がありますね。。。
HTMLのパース
HTMLをパースするとは、HTMLを解析する、という意味で、HTMLページ内のタグや属性を解析して、プログラムで利用できるようにします。
とりあえずここでは、実験的にヤフーファイナンスのヘッドラインニュースの見出しを取り出して表示してみようと思います。
ヤフーファイナンストップページの「ヘッドラインニュース」のページは以下のような感じ。
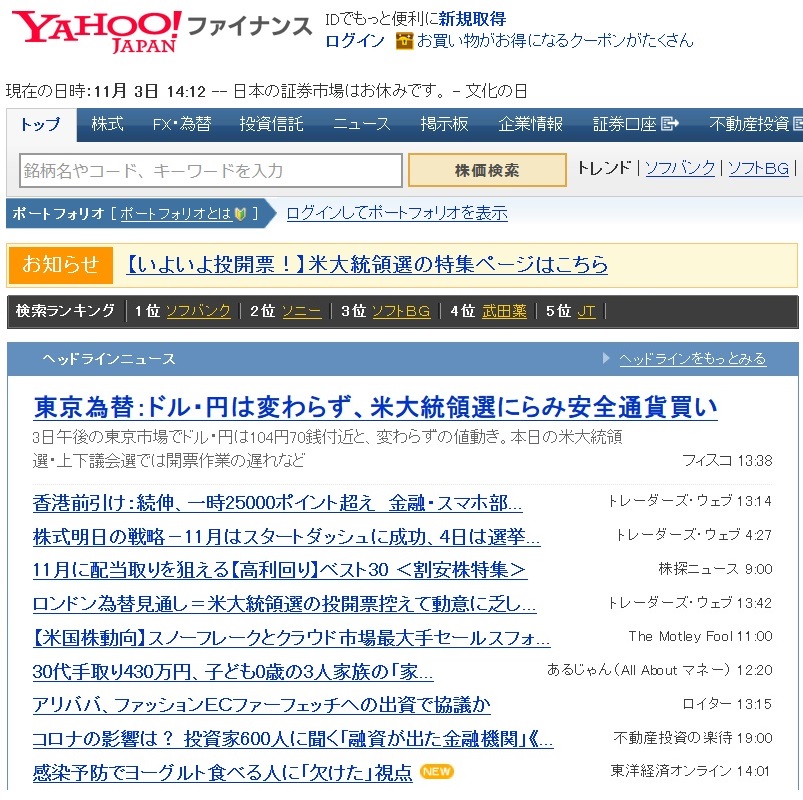
ヤフーファイナンス
とりあえず、このページのソースを見て、それっぽい箇所を探します。
なにげにこれが一番大変かも。。。
探すと、以下の箇所が該当しているようです。

ヤフーファイナンス
そして、見つけた個所をWebスクレイピングするためにPythonのプログラミング文に追加していきます。
まず、bs4からBeautifulSoupをインポートします。
そして、インポートしたBeautifulSoupを使用してHTMLをパースして、パースした結果を変数「soup」に格納します。
その後、findメソッドを使用して、先ほどヤフーファイナンスのページのソースで確認したHTMLのタグとクラスを指定して取り出します(classとyjMSt ymuiListTop)。
で、get_textでニュースのタイトルを取り出します。
実行してみるとこんな感じで、ニュースのタイトルが抽出できます。
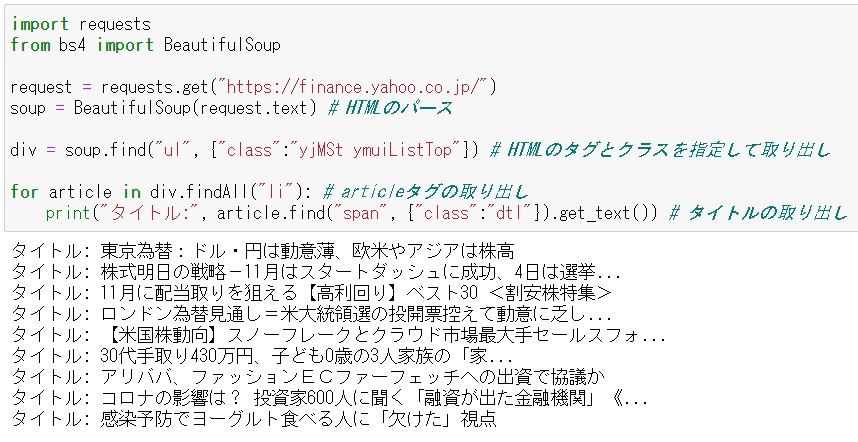
ヤフーファイナンス
今回はなんとなく例文を使ってタイトル抽出できましたが、自分では意味がよくわからず、例文のプログラムをちょこっと触ってみて実行できた感じなので、もっと勉強して、自分で自由自在に操れるようにならなければいけないですね。。。